2012
International Conference on Computer & Information Science (ICCIS)
Bayesian Spam Filtering for Vietnamese Emails l
I 2 Vu Duc Lung , Truong Nguyen Vu University of Information Technology- Vietnam National University Ho Chi Minh City 2 Institute of Applied Mechanics and Informatics, Vietnam
[email protected],
[email protected]
Abstract-
Spam
filtering
is
seen
as
the
considerable
concern to the researchers, and there are some techniques and email filtering systems are implemented. They are, however, not so effective for Vietnamese language. Although methods for filtering English spam email can be still used in Vietnamese language, but Vietnamese has its own particular characteristic. The biggest difference is a signified word in Vietnamese usually a compound.
When
a compound used in
spam
email
is
separated into single words, it becomes words that are usually used in both spam and ham emails. This leads to the difficulty for the system to filter spam emails. The objective of this paper is to present a new model using the application of Naive Bayesian algorithms to analyze the segmentation of Vietnamese language. The process of demonstration and evaluation of this model
shows the
feasibility of this
technique
in
filtering
Vietnamese email.
I.
INTRODUCTION
The most difficulty in filtering Vietnamese spam email is the word segmentation process. Despite the fact that Vietnamese originates from Latin, it has some unique features. A Vietnamese single word always includes one sound or one syllable while an English single word can contain several syllables. For example the word "bac" (uncle) consists of one sound while the word "uncle" consists of two sounds "Dr( and 'kl". In English, a word is defined as: "the correlation of a group of meaningful characters, separated by a space in the sentence" (Webster dictionary). For example, in this English sentence "you are a teacher", 4 words can be used separately, "you", "are", "a", "teacher" and one word has its own meaning. This is different compared with Vietnamese, the sentence "you are a teacher" can be translated into Vietnamese as "Bl;Illla giao vien". In this case, 3 words are taken, "Bl;Ill- you", "Ia - is", "giao vien - teacher", and the word "giao vien" is formed from 2 single words, "giao" and
"vien". Because of this difference between Vietnamese and English, a word mainly used in the spam email but when it extracted to the single words, then these single words may be widely used in good email. For instance, the Vietnamese word "khuySn maI" (promotion, special offer) is often used in Vietnamese spam email, but when it is separated into "khuySn" (means 'advice', 'encourage' or 'recommend') and "mlli"(until, till, foever) then these words could be used in many good email. The majority of Vietnamese vocabulary is composed of two or more words [I]. This means that it often requires more than one word in Vietnamese to make a meaningful word. To distinguish the concept "word" in English from this concept in Vietnamese, we will call word in Vietnamese 978-1-4673-1938-6/12/$3\.00 ©2012 IEEE
[ 190]
as a token. In order to make it clear, we can categorize Vietnamese token into single words and compounds. This paper will present the feasible technique to extract the tokens in the Vietnamese texts without attention to the meaning and application of Naive Bayesian to filter Vietnamese spam email. The paper includes 5 main parts: introduction, researching overview, approach and implementation process, experimental results, conclusion and further work. II.
RESEARCHING OVERVIEW
Although spam filter is considered a problem, it has been solved effectively by many researchers [8]. In the scope of this paper, the solutions just focus on Vietnamese spam emails. For the Vietnamese environment, it is still the problem requires the attention of many people. It can be said that the big obstacle for the successful technique is the different structure between Vietnamese and English, which is mentioned in the previous part and in [2, 3]. Basing on the research results of Foo and Li [4], Le [5], H.Nguyen et al [6], the fact of processing Vietnamese is guided to 2 directions of researching: In the approaching technique basing on "word", there are 3 main groups based on statistics, dictionary and the combination from different technique. This will help to extract words from the whole sentence. The solution from the statistical technique requires the information about term, word or character frequency, the probability of the simultaneously appearing of data. Therefore, the effectiveness of this method partially bases on the specific data being used, but this source is not large and comprehensive enough (There are few aspects, different topics) In the dictionary technique [2, 3], each segment of the text is mutually compared basing on the dictionary, however, the process of setting up the dictionary for each word with the specific Vietnamese meaning cannot be at the completely level and achieve the feasibility. The method bases on the combination of different techniques to make use of the advantage of all the solutions. Or in other word, to achieve the feasibility for this model, approaching methods on words need to have the lexicon set or the scale of training data is large and reliable enough. The approaching technique basing on "single word" in Vietnamese can be divided into 2 small groups: uni - gram (for only single word) and n-gram (for both single word and compound word). This technique seems to be simple but it has contributed effectively to processing Chinese [4].
2012
International Conference on Computer & Information Science (ICCIS)
In the other paper, H.Nguyen et al [6] have made use of the information directly from the internet and applied the genetic algorithm to find out the most optimized segments. III.
ApPROACH AND IMPLEMENTATION PROCESS
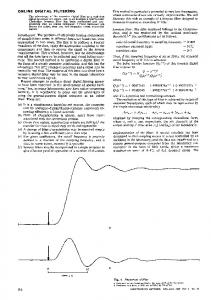
There are a variety of meanings of a single word in Vietnamese that causes difficulties to researches in fields concerning the semantic of Vietnamese language. Until now, there is not any precise statistic to specify the common characteristics of the Vietnamese spam email. As our statistic, the major Vietnamese spam emails usually focus on advertisements. The common characteristics of the approaching methodology will be presented as below. 3.1Mainscope Considering a document D including nwords D � s /S2 s". The objective of this process is t o analyze D into m sentences D= ZlZ2'" Zm, where vai Zk= Si.... Sj ( 1� k� m, 1� i, j� n), including the single words and the compound words. Corresponding to each sentence, it is analyzed into many tokens. Simultaneously, we build a list of the single words and compound ones frequently used in the Vietnamese emails without studying their meaning. From this result, the NaIve Bayes algorithm basing on the analyzed words set is used to classify the kind of Vietnamese emails. In this paper, each email will be in one of two kinds: spam (email is unsolicited and sent in bulk) and ham (in opposite of spam). The Vietnamese email filtering procedure is described as the following model. • • • •
Database token
--------------------
� I
: : Stage 3: self-learning : �--------------------update the frequency of the existing tokens
Figure I. Vietnamese email filtering model
The process consists of three major stages: The first stage is used for pre-processing and analyzing the received Vietnamese email into the single words and the compound words. The second stage applies the NaIve Bayesian algorithm basing on the analyzed tokens to calculate the probability of spam or ham email. The last stage is the token self-learning process after the kinds of email such as spam, or ham are identified.
parts of the system: learning part and filtering part. This process is generalized as follow: Input the Ts set consisting of the training data that belong to one of classes, spam or ham. This set is chosen during the initial phase and also updated continuously. For each training example T E Ts, the supporting vector VT of the token frequency relations will be built basing on the following steps: The pre-processing stage is used to reject all formats of HTML language. Rejecting the general Vietnamese tokens such as "thi", "la", "rna", "cae", "nhung", etc, and the conjunctions such as "tuy nhien" (however), "m�c du" (though), "VI the" (so), "khOng nhitng, rna con" (not only, but also), etc, so that the performance of splitting words processing can be improved since these words are always presented in almost emails, therefore they will not affect on the classification process. Rejecting the words being low presented frequency (these words do not play a role in the email kind identification process). Rejecting the words which are shorter than two characters such as "@", "?", "#", "&",etc. The next stage is to transfer the sentences of the email into the standard sentences of which the single sentence will be separated by the blank, the question mark (7), exclamation mark(!) or quotation marks (") will be replaced by the dot (.) Basing on the property of each single word in the standard single sentence that is separated by the blank, the single word splitting phase is performed. Afterward, these single words and their presented frequency in the email are saved into the database (the coincidental single words in an email will be removed and only counted as one time). The word learning phase occurs during the spam and ham emails training procedure. For instance, the Vietnamese sentence "H9C sinh h9C sinh h9C" will be split into two single words that are "h9C" and "sinh" At the end of this analysis stage, the single words will be collected and each single word has the unique identification (ID). Corresponding to each ID, it has two presented frequencies in spam and ham emails. Next step, the process of extracting the compound words from the single sentences will be described. As mentioned above, in Vietnamese, besides the single words, the compound words are also utilized. After the single word analysis phase is completed, the compound word analysis phase will be performed. In order to analyze the compound words, each Vietnamese email will be extracted into each single sentence. Corresponding to each single sentence, the single words of its will transfer into the vector of ID (d/ d2 dq) that includes the single words di (where i �q). Two adjacent single words di and di+1 will create a compound word g = "di di+/ . This step will continue until approaching the end of this sentence. Whenever a compound word is found, the presented frequency of this word will be increased by 1. • • •
"
3.2 Tokenextractor In Figure 1, the first stage is the process of extracting tokens from each email. This stage will be used in two main
[ 191 ]
2012
International Conference on Computer & Information Science (ICCIS)
This stage will continue performing until all the single sentences in the email are processed. At the end of the training procedure, a set of the compound words and their presented frequencies are achieved. A compound which occurs more often than a given threshold f3 will be considered as a standard compound. The threshold f3 of each compound giis defined by the following
/l= Tg T,t
(1)
formula: Where: Tq - the sum of all sentences containing the compound word g ="di di+1 " ; T" - the sum of all sentences containing the single word di The process is done after the compound words splitting phase is already performed through the email training procedure. With a training set of Vietnamese spam and ham, two module for separating the single word and compound words are used in order to create a dictionary of single and compound words. This module also counts the frequency of every word in these emails. For single word, we will get an absolute accurate dictionary because of if we consider in term of form, then Vietnamese is the same as English. In contrast, we will base on the frequency appearance of two single words consecutively to form a compound word. After all training data, the Vietnamese dictionary containing single words and compound words will be built. This research focuses only on filtering Vietnamese spam email with one word or two-word compound. The reason for that is these two kinds of Vietnamese vocabulary occupies more than 80% of the total (Vietnamese linguistics [7]). 3.3 Classifier In the second stage, the Bayesian algorithm is used to classify each email into one of two classes: spam or ham. According to the Bayesian theorem, for each documentD (email), we will calculate a probability thatD may belong to class Ci as following:
P(c. I D) =
PCC') *P(D I C,)
I
(2 )
P(D)
Where: D is a document (an email) need to classify Ciis one of classes in class set: C/, Cb ..., Cm Under Naive Bayesian assumption, probability of each word in the documentD is independent of the context in that it appeared and it is also independent from the location of the words in the document. Probability P(DIC;)is calculated from the frequency of single words wi (word) in the documentD:
P(DIC)=I1P(wjIC,) kj