DISCRIMINATIVE RESOLUTION ENHANCEMENT IN ACOUSTIC MODELLING Jacques Duchateau∗, Kris Demuynck and Patrick Wambacq Katholieke Universiteit Leuven - ESAT Kardinaal Mercierlaan 94 B-3001 Heverlee, Belgium E-mail:
[email protected] ABSTRACT The accuracy of the acoustic models in large vocabulary recognition systems can be improved by increasing the resolution in the acoustic feature space. This can be obtained by increasing the number of gaussian densities in the models by splitting of the gaussians. This paper proposes a novel algorithm for this splitting operation. It is based on the phonetic decision tree used for the state tying in context dependent modelling. Advantage of the method is that it improves the capability of the acoustic models to discriminate between the different tied states. The proposed splitting algorithm was evaluated on the Wall Street Journal recognition task. Comparison with a commonly used splitting algorithm clearly shows that our method can provide smaller (thus faster) acoustic models and results in lower error rates.
1. INTRODUCTION One way to improve the accuracy of the acoustic modelling in large vocabulary continuous speech recognition is by enhancing the resolution in the acoustic feature space. In the case of acoustic modelling that is based on mixtures of gaussian densities, this means that the number of gaussians is increased. Therefore, splitting of the gaussians in acoustic models has attracted the interest of several research groups in the recent past [1, 2, 3, 4, 5]. There are two main questions to answer in this type of research: which gaussians will be selected for splitting, and how will each of the selected gaussians be split. Concerning the which problem, different solutions are proposed. In [1], gaussians with a high occupancy are selected, with the occupancy being defined as the number of data frames in the training data material that are assigned to the gaussian. The algorithm in [4] selects those gaussians that result in the maximal likelihood increase by the split. ∗
Supported by the research fund of the K.U.Leuven
In [2] and [5], the criterion to decide which gaussians to split is based on MMI (Maximum Mutual Information). In this paper (similar to [3]) a simple solution to this first problem – which gaussians to split – is used: all gaussians are split, this way increasing the number of gaussians by a factor of two. The only exceptions are the gaussians for which the occupancy is too small as this would result in gaussians that can not be estimated reliably. Once decided which gaussians are to be split, the second problem pops up: how to split those gaussians. The solution to this problem is not straightforward: if for instance a gaussian is replaced by two exact copies of that gaussian, these two gaussians will never diverge by further model training. This second problem – how to split gaussians – is addressed in this paper. A novel, discriminative splitting procedure is proposed. It is based on the phonetic decision tree that is used for context dependent state tying. In section 2, different methods to split a gaussian are discussed, comparing the methods from the literature with the proposed algorithm. Our algorithm is explained in detail in section 3, and evaluated in sections 4 (experimental setup) and 5 (results). Finally some conclusions are given in section 6. 2. METHODS FOR SPLITTING In the literature, different methods are proposed to split a gaussian density. Splitting a gaussian means that two separate gaussians have to be initialised which will be refined by further training of the acoustic models. A trivial method is used in [1] and [3]. The splitting problem is solved by initialising the two new gaussians with different mean values, which are separated proportionally to the square root of the variance of the gaussian. In fact, the two gaussians are initialised rather randomly: nor the underlying real distribution of the gaussian is used, nor the position of different classes (states, phones) to discriminate between. In the result section of this paper, our algorithm will be compared with this method.
Occupancy subtree: 100
Question Yes
No
Occupancy subtree: 0
Occupancy subtree: 100
Question Yes
No
Occupancy subtree: 10
Occupancy subtree: 90
Question Yes
No Occupancy subtree: 40
Occupancy subtree: 50
Question Yes Occupancy subtree: 30
No Occupancy subtree: 20
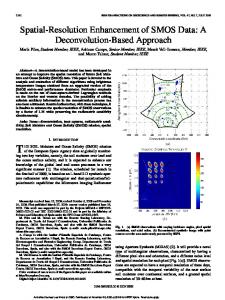
Figure 1: Splitting of gaussians based on a decision tree
In papers that select the gaussians to be split based on MMI ([2],[5]), the one gaussian is initialised as the ML (maximum likelihood) estimate whereas the other gaussian is initialised as the MMI estimate. By the use of the MMI estimate, an improvement in discriminativity is introduced. However nothing is known about the mutual position of both new gaussians. Drawback of the above methods is that a gaussian that is split has to be replaced by both new gaussians in the mixtures in which it is used. This results in an increase of the number of components in the mixtures of gaussians that model the state distributions. The following methods, worked out specifically for modelling with tied gaussians, overcome this problem. The method in [4] works as follows. When a gaussian is used in different states, separate gaussians are estimated for each of these states, as if there was no tying of the gaussians. Then the estimated gaussians – and the corresponding states – are clustered in two groups, and for each group a new gaussian is initialised (ML estimate). In the mixtures, the original gaussian is replaced by only one of both new gaussians, namely the one for the correct group of states. Using this method, discrimination between the states is enhanced. In this paper we propose a new method for splitting
gaussians, using phonetic decision trees. It is based on the same idea as the method in [4]: the states in which a gaussian is used are divided in two groups, then the gaussian is cloned and each group of states uses one of the clones. Both gaussians will diverge automatically since they are used in different states. So our method has the same plus-points as the method in [4]: the number of components in the mixtures for the states does not increase, and the discrimination between the tied states is enhanced. The difference with the method in [4] is the way in which the states that initially share a given gaussian are divided into two groups. In the proposed method, explained in detail in the next section, this division is based on the phonetic decision tree with which the state tying for the acoustic models was defined. The advantage over the method in [4] is that it avoids the poor estimation of different gaussians for each of the states. 3. TREE BASED SPLITTING The aim of the tree based splitting algorithm is to find a group of similar states in one subtree of the tree that will share the first clone of the gaussian. This way the discrimination between these states and the other states in the tree, which will use the other clone, is enhanced. In order to
reach a maximal effect, a division is selected that gives an optimal balance between the occupancy of both new gaussians. Figure 1 shows how our decision tree based algorithm divides the states that use a given gaussian in two groups. First all states are looked up in which the gaussian is used, this in order to be able to calculate quickly the total occupancy for the gaussian in all leaves that belong to any subtree. Then the algorithm starts investigating the tree at the root, and at each binary question it descends in the direction of the subtree with the highest total occupancy, as the arrow in figure 1 indicates. It stops when an optimal balance is found between the occupancy in the current subtree and the total occupancy in the lost (not investigated) subtrees. For the example in figure 1, it stops at the subtree with total occupancy 50. The states in this subtree will use one gaussian, the states in the subtrees with total occupancy 40 and 10 will use the other, resulting in a perfect balance. The investigation of the tree is not stopped at the subtree with 90 or at the subtree with 30 as total occupancy because these choices give a worse balance (90/10 and 30/70 respectively). Note that a gaussian is not split if any of the new gaussians has an occupancy that is too low to estimate it reliably. This can occur if the original gaussian has a low occupancy but also if the gaussian is used in only one state (or if it has only a very low occupancy in the other states).
dependent models are constructed. The baseline acoustic models used for the experiments described below make use of 20254 tied gaussians and 6559 tied states with (on average) 193 gaussians per state. From these baseline models, reference models with 20k gaussians are constructed as follows. First the number of gaussians per state is reduced using the algorithm we developed based on the occupancy criterion (see [8]). Then the reduced models, with 132 gaussians per state, are trained with one ML training step. The reason why the reduced models are used as reference is that they are faster than the baseline models, but without loss in recognition accuracy. As baseline for the experiments with 40k gaussians however, the models with more components in the mixtures are used because mixture components can become less or more important by the splitting. Thus maybe some components that are useful for the models with 40k gaussians are lost in the reduced reference models. The results of the reference models are given on the first line of table 1. For the 5k word experiments, our recognition system runs in real time on a dual processor 450 MHz Pentium II computer. The calculation of the probabilities of the tied states takes 90% of the available computing power of one processor, the time-synchronous beam search takes 100% of the other. For the 20k word experiments, the time needed for the beam search increases to 200% of one processor.
4. BASELINE RECOGNITION SYSTEM 5. EXPERIMENTAL RESULTS We evaluated our algorithm for the splitting of gaussians on the speaker independent Wall Street Journal (WSJ) recognition task. Standard bigram and trigram language modelling provided by Lincoln Laboratory for the 5k word closed vocabulary and the 20k word open (1.9% OOV rate) vocabulary is used. The results – word error rate (WER) – are given on the November 92 evaluation test sets with non verbalised punctuation. They contain 330 sentences for the 5k word task, and 333 sentences for the 20k word task. The signal processing gives 12 Mel scaled cepstral coefficients and the log energy, all of them mean normalised and augmented with first and second order time derivatives. The resulting 39 features are decorrelated using the algorithm described in [6]. Our acoustic modelling is gender independent and based on a phone set with 45 phones, without specific function word modelling. No cross-word phonetic rules are used to adapt phonetic descriptions depending on the neighbouring words. The acoustic models with tied gaussians are developed from context independent models as described in [7]. Based on one global phonetic decision tree, context and position
In this section, two methods for splitting of gaussians are evaluated and compared. The first is the trivial method in which the means for the two new gaussians are initialised by adding and subtracting shift times the square root of the variance of the gaussian. Two values for the shift were investigated: 20% (as in [1]) and 50%. The second method is our decision tree based method, as described in this paper. The results of the comparison are summarised in table 1. The acoustic models for the experiments are obtained as follows. First the splitting method is applied on the baseline model (the one with 20k gaussians and 193 gaussians per state) and one training step is executed. Then the models are reduced based on the occupancy criterion (o2 in the table indicates an occupancy threshold of 2 data frames). Finally one more training step follows. It can be seen from the table that absolute improvements between 0.1% (5k words, trigram) and 0.5% (20k words, bigram) can be obtained using 40k gaussians instead of 20k gaussians. On the 5k word experiments, the recognition results are approximately the same for both splitting methods. However, our splitting method gives a clear improvement over
Gaussians 5k words 20k words per state bigram trigram bigram trigram Reference models (20241 gaussians) 132 (o2) 4.32% 2.48% 10.21% 8.49% 20% shift of the mean (40152 gaussians) 237 (o1) 4.09% 2.41% 10.01% 8.26% 183 (o2) 4.09% 2.35% 10.01% 8.28% 128 (o4) 4.07% 2.60% 10.23% 8.47% 50% shift of the mean (40152 gaussians) 229 (o1) 4.00% 2.37% 10.08% 8.33% 179 (o2) 3.98% 2.41% 9.80% 8.28% 126 (o4) 4.17% 2.60% 10.05% 8.26% Decision tree based (39770 gaussians) 145 (o1) 4.04% 2.41% 9.69% 8.15% 122 (o2) 4.09% 2.41% 9.71% 8.20% 93 (o4) 4.00% 2.45% 9.94% 8.15% Table 1: Splitting of gaussians: evaluating different algorithms on WSJ (WER given)
the method with mean shift for the 20k word experiments. Also, the resulting models are smaller and thus faster when our splitting method is used: the number of components in the mixtures of gaussians does not increase by splitting as the original gaussian is replaced by only one of the two new gaussians. The models found using the method with mean shift can not be reduced further without losing accuracy. This can be seen from the results with reduction using occupancy threshold 4: for the models based on splitting with mean shift, 3 out of 4 results get worse by about 0.2%. These results should be compared with the models based on our method and reduction using occupancy threshold 2, as these give about the same number of gaussians per state.
6. CONCLUSIONS In this paper, we proposed a novel method for the splitting of gaussians in acoustic models used for large vocabulary recognition. The method is based on the decision tree which is used to define the state tying in the context dependent models. A first advantage of the method is that it improves the capability of the acoustic models to discriminate between the different tied states. This results in improved recognition rates, as was shown on the WSJ recognition task. A second advantage which is inherent in our splitting method is that it provides smaller, thus faster acoustic models compared with other methods.
7. REFERENCES [1] S.J. Young and P.C. Woodland. State clustering in hidden Markov model-based continuous speech recognition. Computer Speech and Language, 8(4):369–383, October 1994. [2] Y. Normandin. Optimal splitting of HMM gaussian mixture components with MMIE training. In Proc. International Conference on Acoustics, Speech and Signal Processing, volume I, pages 449–452, Detroit, U.S.A., May 1995. [3] J. Simonin, S. Bodin, D. Jouvet, and K. Bartkova. Parameter tying for flexible speech recognition. In Proc. International Conference on Spoken Language Processing, volume II, pages 1089–1092, Philadelphia, U.S.A., October 1996. [4] D. Willett and G. Rigoll. A new approach to generalized mixture tying for continuous HMM-based speech recognition. In Proc. EUROSPEECH, volume III, pages 1175–1178, Rhodes, Greece, September 1997. [5] R. Schl¨uter, W. Macherey, B. M¨uller, and H. Ney. A combined maximum mutual information and maximum likelihood approach for mixture density splitting. In Proc. EUROSPEECH, volume IV, pages 1715–1718, Budapest, Hungary, September 1999. [6] K. Demuynck, J. Duchateau, D. Van Compernolle, and P. Wambacq. Improved feature decorrelation for HMMbased speech recognition. In Proc. International Conference on Spoken Language Processing, volume VII, pages 2907–2910, Sydney, Australia, December 1998. [7] J. Duchateau, K. Demuynck, and D. Van Compernolle. Fast and accurate acoustic modelling with semicontinuous HMMs. Speech Communication, 24(1):5– 17, April 1998. [8] J. Duchateau, K. Demuynck, D. Van Compernolle, and P. Wambacq. Improved parameter tying for efficient acoustic model evaluation in large vocabulary continuous speech recognition. In Proc. International Conference on Spoken Language Processing, volume V, pages 2215–2218, Sydney, Australia, December 1998.